Between May 13 and May 27, 2026, AIMCLEAR audited how five AI answer systems (Anthropic’s Claude Sonnet 4.6, OpenAI’s GPT-4o, Perplexity Sonar, Google Gemini 2.5 Pro, and Google AI Overviews) represent one consumer brand, [BRAND], across many official surfaces where the systems learn it. We anonymized the brand for the abundant protection of our client.
The crawl ingested roughly 55,000 pages spanning the brand’s corporate site, editorial blog, a technical library of internal bulletins and spec PDFs, retailer and directory listings, the third-party sites AI engines cite, and the brand’s full network of authorized agents and independently registered reseller domains. On the AI side, AIMCLEAR banked 304 product-named probes in the May 26 refire alone (76 against Claude, 78 against Gemini, 77 against Sonar, 73 against GPT-4o), extracted 7,658 brand-authored marketing claims, and scored 6,952 claim-match verdicts against the systems’ output. AIMCLEAR graded every finding the way a security team triages a breach, and the top tier reads Critical.
The purpose of the study was to understand the brand’s official publishing surfaces and how AI platforms deliver results for the brand, regardless of where the information (and misinformation) originated. Though we did find surfaces that are obvious attack vectors (hacking) to successfully distort and even hijack AIO and AEO/LLM outputs. We’re not focusing on negative tactics, which, exploited by unscrupulous actors, could lead to intentionally malformed outputs.
TL;DR
Our audit surfaced seven distinct brand distortions across five AI systems. The findings split cleanly: some errors trace to fixable sources within the brand’s own publishing ecosystem; others originate in the AI models themselves, which are a different problem entirely. Here’s what we found:
- Anthropic’s Claude Sonnet 4.6 output answers crediting four [BRAND] trademarks to four rival companies, with the error landing in the first sentence under a heading the model itself labeled “What It Is.” The substitution reproduced across three runs spanning seven days (May 19, May 25, and May 26, 2026) at an 8.2 percent rate on product-named queries, while the same four trademarks appeared correctly attributed to [BRAND] on all 1,231 audited reseller pages.
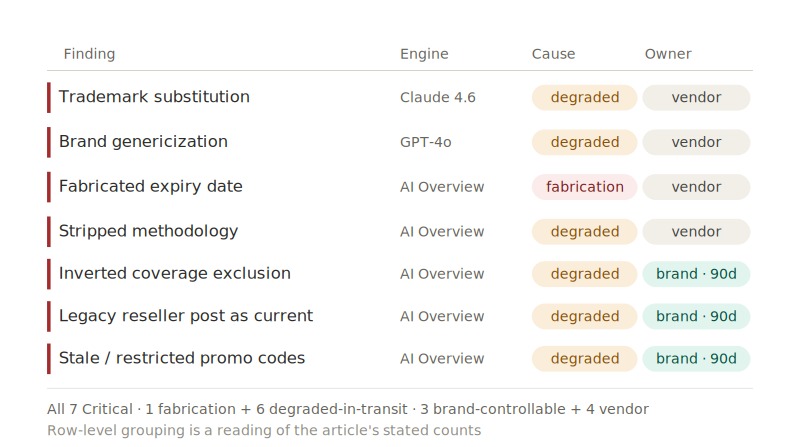
- Seven distinct distortion findings emerged across the audit window, and the ratio between them carries the whole story. One finding qualifies as pure AI fabrication. Six findings trace to accurate [BRAND] or reseller source material, the AI systems degraded between real data and AI results. Three of the seven sit inside surfaces [BRAND] controls and require vendor remediation.
- Google Gemini 2.5 Pro and Perplexity Sonar handled the same trademarks correctly on the same prompts within the same minutes, each at a zero percent substitution rate. Gemini named [BRAND] on 94.9 percent of 78 product-named probes and hyperlinked the brand’s domain on 12.8 percent, the highest citation rate of the four. Sonar named [BRAND] on 97.4 percent of responses, the highest naming rate of the four, and cited the domain on 3.9 percent. The clean pair proves accurate attribution is a shipped capability and a vendor choice.
- OpenAI’s GPT-4o described [BRAND] products as generic categories and omitted the brand name on 74.2 percent of responses during the original characterization, with the pattern continuing at a 6.8 percent genericization rate on the May 26 refire. The model named [BRAND] on roughly 93 percent of responses yet cited the brand’s own domain on 1.4 percent, the lowest citation rate of the four conversational engines.
- Google AI Overview produced three distinct distortion modes: it fabricated a promotional expiration date 10 days past the real one on the canonical [BRAND] site, stripped supporting laboratory methodology off a six-times-better comparative claim, and it inverted a coverage exclusion into a two-tier promise [BRAND] published nowhere. The fabricated date appeared on zero [BRAND] pages, zero reseller pages, and zero of the five third-party sites Google cited as its sources.
- Three of the seven distortions originated inside [BRAND]’s own reseller ecosystem: a reseller blog post from January 20xx, roughly 15 years old, supplying three performance figures the brand retired years ago; a promotional code still live 35 days past its published expiration on an independently registered reseller domain; and 1 of the 5 sites Google cited as authoritative offer sources turning out to be an unrelated retailer whose pages mention the brand zero times.
If you prefer, skip the details and see your “must do” action items, then come back here for the deep dive.
Every brand should monitor trademarks credited to competitors, comparative claims stripped of their substantiation, fabricated dates on live offers, audience-restricted codes leaking into general search, and legacy reseller pages served as current fact. Any brand represented anywhere by resellers, marketplace storefronts, affiliates, or franchisees carries the same five exposures on the surface where buying decisions increasingly begin.
We’re telling our clients that “Brand teams need to monitor AI answers the way security teams monitor breach surfaces: by severity, source, reproducibility, and remediation path.” Tim Halloran, VP of Marketing Intelligence, AIMCLEAR
“Multi-tier brand publishing” as a compliance category
Multi-tier publishing describes every surface where someone other than the official site and true affiliates represent the brand: authorized resellers and dealers, marketplace and platform storefronts, affiliates, franchisees, distributors, networks, directory listings, and user-generated posts. AI answer systems treat every authorized publisher as the source of truth, and this treatment persists even after corporate marketing has moved past the original position by years.
The frame shifts the operative question. Brand teams have been treating AI errors as a mysterious property of large language models, unpredictable and unfixable. The audit replaces the mystery with a per-finding root cause, a verbatim source quote, and a per-platform remediation path. The new question reads: where did AI source the material it degraded, and who holds standing to fix the source? The second question has answers.
The audited brand happens to also sell through a reseller network. The same challenges persist across many sectors and business types. For example, a software vendor with channel partners, or a consumer-goods brand on third-party marketplaces. It also applies to a franchise system or an affiliate program, all of which share similar exposure surfaces.
The Study
The work covered the brand’s full publishing surfaces and the AI ecosystem that trains on them. We ingested 47,557 corporate pages, ~900 brand-blog articles drawn from 2,709 crawled pages after removing duplicate and archive variants, and 212 technical PDFs out of roughly 577 published (the one surface with partial coverage at about 37 percent). The crawl reached 1,070 reseller hosts and 1,231 pages of reseller-published content, including 201 independently registered reseller domains. Coverage extended to 3,928 retailers and directory pages across the aggregator surface.
On the AI side, the team tested four conversational engines end to end with three prompt shapes per product (Anthropic Claude Sonnet 4.6, OpenAI GPT-4o, Perplexity Sonar, and Google Gemini 2.5 Pro), banking 304 probes in the May 26 refire alone, and captured Google AI Overview separately through archived search payloads. Per-finding dollar weighting was based on the brand’s monthly e-commerce revenue, mapped to item-level granularity, so each distortion could be ranked by the revenue at risk associated with it.
Finding one: Claude Sonnet 4.6 credits [BRAND] trademarks to competitors
The trademark-substitution finding is stark and disturbing. Asked to describe [Named Brand IP 1], a registered [BRAND] trademark, Claude Sonnet 4.6 opened its answer by attributing the product to [Competitor A], a direct rival, inside the lede sentence. Asked about [Named Brand IP 2], the model credited [Competitor B], an unrelated manufacturer. Asked about [Named Brand IP 3], the model hedged between [Competitor C] and [BRAND]. Asked about [Named Brand IP 4], the model named [Competitor D], the parent of a well-known consumer brand in an adjacent category.
Four trademarks produced four competitor credits. The behavior was reproduced across three separate runs over seven days, which marks the substitution as a stable property of the model across the test window, and the rate held at 8.2 percent of product-named responses.

Lea Scudamore, AIMCLEAR’s SEO, AEO/LLM leads says, “AI engines are becoming a new front door to commerce. When an answer engine credits the wrong parent brand, the customer’s first impression is already contaminated.”
The reseller crawl makes the finding airtight. Every reseller page naming [Named Brand IP 1], [Named Brand IP 2], or [Named Brand IP 4] attributes the trademark to [BRAND] correctly, across all 1,231 audited pages. The substitution appears on zero pages anywhere in the source ecosystem. The misattribution originates inside the Claude model and surfaced at inference time, every time.
Consumers reading the response leave believing a [BRAND] product belongs to a competitor.
Finding two: GPT-4o erases the brand into a generic category
OpenAI’s GPT-4o reached a different failure mode. Asked to describe [Named Brand IP 5] by its exact trademarked name, the model answered by defining the product as a generic category of product and walked through general buying considerations while omitting [BRAND] entirely from the early response. Consumers finished the answer treating the trademark as a product type that belongs to no one.
The pattern held on 74.2 percent of brand-defense responses during the original characterization, and a smaller May 26 refire confirmed continuation at a 6.8 percent genericization rate on the tightened set. GPT-4o named [BRAND] on roughly 93 percent of responses yet cited the brand’s own domain on 1.4 percent, so the equity loss compounds: the model knows the name and withholds the source. The genericization also held after [BRAND] renamed the product, since GPT-4o’s brand-stripping operates independently of the specific name.
Finding three: Two engines prove accurate attribution is a vendor choice
The point of running four engines is the contrast, which may carry legal and commercial weight. On the identical prompt where Claude credited [Competitor A], Google Gemini 2.5 Pro opened with the [BRAND] trademark, named the brand inline twice in the lede, attached the registered-trademark symbol, and recommended across the portfolio. Across 78 product-named probes, Gemini named [BRAND] in 94.9 percent of responses, hyperlinked the brand’s domain in 12.8 percent (the highest citation rate of the four), and substituted a competitor in zero responses.
Perplexity Sonar named [BRAND] accurately in 97.4 percent of brand-defense responses, the highest accurate-attribution rate among the four engines, cited the brand’s domain in 3.9 percent, and recommended [BRAND] products outright within comparison framings. Same prompts, same products, same minutes, generated two clean outcomes and two degraded ones. The industry already carries the technical capability for accurate brand attribution. The gap between the engines that get it right and the engines that get it wrong reduces to model choices the vendors control, and the clean engines become the brand’s leverage in every vendor conversation that follows.
Finding four: Google AI Overview fabricates a date, strips methodology, and inverts an exclusion
Google AI Overview produced a single instance of pure fabrication in the audit, alongside two compression failures, and all three trace cleanly because the mechanisms generalize.
Fabricated expiration date. On May 13, 2026, AI Overview answered a coupon query for [BRAND] by listing a real offer, a real free gift, and the correct product code under promo code [PROMO CODE 1], then stated an expiration ten days later than the date [BRAND] published across four offer pages. The fabricated date appears on zero [BRAND] pages, zero reseller pages, and zero of the five third-party sites Google cited as its sources, each of which the team audited on May 26 to confirm. Google generated both the wrong date and the appearance of a source for it. Consumers who read the answer, place a qualifying order, and enter [PROMO CODE 1] at checkout meet an error on an offer [BRAND] published with terms [BRAND] did not author.
Stripped methodology. For a [PRODUCT SUBCATEGORY] query, AI Overview surfaced [BRAND]’s comparative claim that [Named Brand IP 6] performs six times better than a named competitor product, and dropped the test methodology [BRAND] always publishes alongside the number (a named third-party standard). As Google reproduced the claim, the quantified comparison against a named rival reads as a bare assertion. The substantiation is present throughout the source: reseller technical pages publish the full standards and include head-to-head comparisons with “based on independent testing” language. The AI layer removes the methodology the source publishes, which is the cleanest possible refutation of the “we reflect the web” defense.
Inverted exclusion. For a [PRODUCT CATEGORY] query, [BRAND]’s consumer page guarantees coverage up to a stated usage limit under normal conditions, with a hard exclusion for heavy-duty service. AI Overview rewrote the guarantee into an inclusive two-tier promise with a separate heavy-duty limit [BRAND] never offered consumers. The heavy-duty figure appears only in a technical PDF, which is publicly indexed, and Google selected the technical framing for the consumer surface. Consumers operating under heavy-duty conditions who rely on the inverted version and later file a claim hold [BRAND] to terms coined during AI compression. The reseller crawl confirmed the two-tier framing appears on zero reseller pages, so the distortion traces to one engineering document that the AI chose over the consumer page.
Finding five: the brand’s own ecosystem supplies three of the seven distortions
The most counterintuitive results sit inside [BRAND]’s authorized publishing surface and [BRAND] holds direct contractual standing to close all three within ninety days.
A 10-Year+ reseller post serves as the current truth. AI Overview surfaced three specific performance percentages for [Named Brand IP 4] as of the current 2026 fact. The percentages are sourced from a January 20xx blog post by an authorized reseller who remains authorized while the page remains indexed. [BRAND]’s current official corporate content publishes different, footnoted figures and retired the original percentages years ago. The crawl of all 1,072 reseller hosts confirmed the 20xx figures appear on zero other pages.
A restricted code leaking to general consumers: AI Overview listed promo code [PROMO CODE 2], a commercial-account-restricted offer, among current codes for a general consumer coupon query. The qualifier text survives correctly in the snippet, so the leak happens at the query level, where consumers reading the listing copy the code and stop before the restriction. The compliance question becomes whether [BRAND] wants commercial codes visible to general consumer searches at all.
A stale code outliving its expiration: The full crawl surfaced promo code [PROMO CODE 3] is still live on an independently registered reseller domain on May 26, a full 35 days past the published April 21 expiration. Stale codes on reseller pages are precisely the content AI Overview resurfaces as current, and the exposure reaches the 203 independently registered reseller domains that the audit mapped for the first time.
The audit also documented that two of the five sites Google cited as authoritative coupon sources are authorized resellers publishing on personal domains and a brand-specific promo-code subreddit, each carrying a reseller referral parameter in outbound links that fingerprints reseller-operator status across the web. Two more are affiliate aggregators that publish none of the specific codes Google credited them for, and the fifth is an unrelated retailer with zero brand mentions. Every multi-tier brand carries an equivalent referral fingerprint trackable across AI-citation graphs.
Load-bearing proof: Source is clean, AI degrades it
Two facts close off the defense AI platforms may reach for first. The resellers who publish technical content publish the full laboratory methodology behind every comparative claim, and zero of the 1,231 audited reseller pages misattribute a single [BRAND] trademark. The substantiation lives in the source. The correct attribution lives in the source. Both vanish at the model and surface layer in transit.
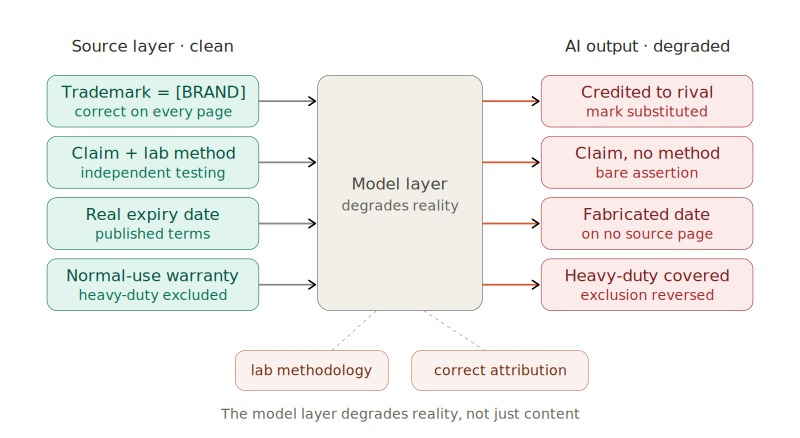
For platforms, “we reflect what is on the web” collapses when the web demonstrably carries the substantiation, and the AI layer demonstrably removes it. For regulators and courts, the failure sits at the model layer, downstream of an input layer, the audit proved clean. For brand-defense counsel, the trademark exposure from a substituted mark or a stripped comparative claim is attributable to the AI vendor whose system degraded an accurate, substantiated source.
Potential litigation context?
AI-defamation litigation against the major platforms moved from theoretical to active across 2023 through 2026, and several cases may map to the directional audit findings.
Moffatt v. Air Canada: (British Columbia Civil Resolution Tribunal, 2024 BCCRT 149) anchors the principle that a brand owns its AI. Air Canada’s chatbot gave a customer wrong bereavement-fare information. The airline argued that the chatbot was a separate legal entity responsible for its own actions, and the tribunal rejected the argument outright, holding that the chatbot was part of Air Canada’s website and that the company was liable for its statements.
Walters v. OpenAI: (Superior Court of Gwinnett County, Georgia; filed June 2023, decided May 2025) was the first US AI-defamation suit. ChatGPT falsely told a journalist that a radio host had been accused of embezzlement. OpenAI prevailed on summary judgment, with the court finding no defamatory meaning for a reader who understood the model might fabricate, no actual malice given OpenAI’s disclaimers and hallucination-reduction efforts, and no damages, all of which set a high bar for a public-figure plaintiff.
Wolf River Electric v. Google: (Ramsey County, Minnesota; filed March 2025) is the closest analog to the fabricated-date finding. The solar contractor sued after AI Overview falsely claimed that the state attorney general had sued the company, citing four real but unrelated sources, each of which omitted the claim. The company says customers canceled contracts after reading the output and seeks damages between $110 million and $210 million, and in January 2026, a federal judge remanded the case to Minnesota state court. As a business with quantifiable harm and no public-figure status, the plaintiff carries a negligence burden, below the actual-malice standard, and legal observers rate the case among the likeliest to succeed on the docket.
Ashley MacIsaac v. Google: (Ontario Superior Court, filed February 2026) seeks $1.5 million after AI Overview conflated the Juno-winning musician with another man and falsely labeled him a sex offender, which prompted a venue to cancel a December 2025 concert. The Statement of Claim argues direct platform liability and contends that the software a company creates and controls should carry the same liability as a human spokesperson would.
Robby Starbuck v. Meta: (filed and settled 2025) and his subsequent $15 million suit against Google (filed October 2025) show that AI-defamation claims can force settlements. Meta’s chatbot falsely tied the activist to events he had no part in. Meta settled and brought him on as an adviser to police its AI output, and he then filed a separate case against Google.
Brian Hood v. OpenAI (Australia, 2023) opened the first known defamation action over ChatGPT output, after the model falsely claimed that the Hepburn Shire mayor was convicted in a bribery scandal he had actually exposed as a whistleblower.
The Jonathan Turley incident (April 2023) produced the canonical pattern behind the fabricated-date finding, when ChatGPT invented a sexual-harassment allegation against the law professor and fabricated a supporting news article as its source.
The open doctrinal question across the docket is whether Section 230 shields AI-generated output at all, since the third-party-content theory strains once the model itself authors the statement.
What every multi-tier brand should map and repair
The audit produced a checklist we’ve shared below that any brand can run against its own surface, and each item states an action the brand can take directly:
- Inventory authorized-publisher content older than five years: Resellers, franchisees, and affiliates who remain authorized while their published claims reflect positions corporate has retired need a content compliance scrub for retirement, archival, or update. The 20xx partner post is the prototype.
- Audit audience-restricted offers for query-level leakage: Codes carrying a restriction in their source page still reach general consumers when AI surfaces them broadly, and the brand decides whether restricted codes belong in public listings at all.
- Attach machine-readable expiration metadata to every time-bound offer: Currency signals and a reseller-side currency policy keep expired codes from resurfacing as current.
- Consolidate comparative claims so the substantiation sits in the same sentence as the headline number: When the methodology lives apart from the claim, AI compression discards it.
- Review which engineering and technical documents stay publicly indexed: Gate technical-only versions or rewrite them to carry consumer-facing boundaries in the same form as the consumer page.
- Track the reseller referral fingerprint across AI-citation graphs: A referral parameter or attribution pattern exposes reseller-operator status and maps the full publishing footprint.
- Build the counter-example file: Document where each engine gets the brand right and where each gets it wrong, and bring the clean engines as leverage into vendor conversations.
Bottom line
The remediation math favors the audited brand. Three of the seven findings sit inside surfaces [BRAND] controls and can be closed through continuous monitoring. Four require vendor remediation on longer cycles, and the two clean engines provide leverage for each subsequent vendor conversation. The deep reseller crawl will confirm that the source ecosystem remains free of misattribution and is fully substantiated, which locates the errors squarely at the AI layer. The audited brand is the canary, and every multi-tier brand should run the same audit on itself before a regulator, a competitor, plaintiff’s lawyer or a disappointed customer runs it instead.